The ability of AI to perceive politeness and kindness is primarily shaped by engineering decisions
This is the third part of the Politeness and AI series (Part 1, Part 2). The earlier articles introduced how polite phrasing can alter embeddings and inference, ie. how even subtle polite tone can have a major effect on the generated response. If you haven’t read part 1 and part 2, I recommend starting there.
Signals in 5 Minutes ⏱️ is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
I had a fantastic journey discovering how AI perceives politeness and compassion. I have conducted dozens of mini-experiments: fine-tuning AI, adjusting vector embeddings and mapping results on a 2D space.
The results confirmed that large language models are highly responsive to tonal variation, but also remarkably fragile.
Even minor changes to preprocessing ora single mistake in the training parameters can completely eliminate the model’s capacity to perceive emotional context. 💔
The multiple layers of data processing, model training, and alignment can introduce distortions, or in some case completely eliminate emotional context. Each layer introduces a risk of flattening the full colour of human expression, resulting in degraded or neutralised tone.
This article explores some of these “danger areas”, where tonality can be lost before, during and after training.
So what stands in the way of politeness?
Let’s zoom out and consider AI models in its 3 stages:
Before Training: When we clean, sanitise and normalise data
During Training: The actual, high-resource training process
After Training: When the user interacts with AI
Preprocessing is the process of cleaning, transforming, and organizing raw data (eg. sentences) into a structured format that is suitable for machine learning algorithms
1. Before Training. (Preprocessing)
Before any model training begins, input text typically undergoes a series of normalisation steps to reduce complexity and improve consistency. While effective for many downstream tasks, these preprocessing operations can inadvertently strip away essential contextual or emotional signals, including tone and politeness.
Normalisation steps have a single goal: reduce the text to its core meaning, so that AI can process and learn from large amounts of text efficiently.
Most of these transformations are “harmless” to tonal variation. Consider the following stop-word reduction:
“I prefer the tiramisu“ ✅
↓
“I prefer tiramisu“ ✅ ← Meaning and tone are retained.
The above reduction preserved both meaning and tone, while decreasing word count by 25%. Great! In large-scale settings, such optimisations contribute to significantly faster training.
However, some of these preprocessing techniques can be actively “harmful” to preserving politeness and subtle tonal variation:
Case folding
Case folding is the process of converting all characters to lowercase. This standardisation helps eliminate superficial variation and ensures that words like "Please" and "please" are treated identically.
However, in tone-sensitive contexts, this step may remove stylistic signals that indicate emotional intent. For example, the same sentence can completely inverse the tonal context, even with polite cues, like “please”:
"Can you PLEASE clean your room?" 👿
↓ turns into ↓
"Can you please clean your room?" ☺️
Although case folding can improve consistency for search and classification tasks, itreduces the model’s capacity to detect tone-related cues. This can be particularly problematic in politeness modelling, where capitalisation may indicate additional emotional charge.
Punctuation removal
Punctuation removal refers to the elimination of characters such as full stops, commas, exclamation marks, and question marks from input text. While this step simplifies tokenisation and reduces vocabulary size, it also removes important cues that guide human interpretation.
Punctuation often carries tone. For example:
"Please." conveys completion and calm ☺️
"Please!" conveys urgency or insistence 👿
"Please..." may suggest hesitation or emotional nuance 🥺
In polite or emotionally expressive text, sentence-final punctuation helps disambiguate intention. Removing it flattens affective structure, making different speech acts indistinguishable to the model. For example:
"I need it now." - may sound firm but composed
"I. Need. It. Now." - suggests controlled urgency
or suppressed frustration
Both convey the same literal message but differ significantly in emotional tone. Without punctuation, these cues are lost. In contexts where tone, deference, or relational cues are relevant, punctuation removal reduces the model’s ability to infer subtle but socially significant distinctions.
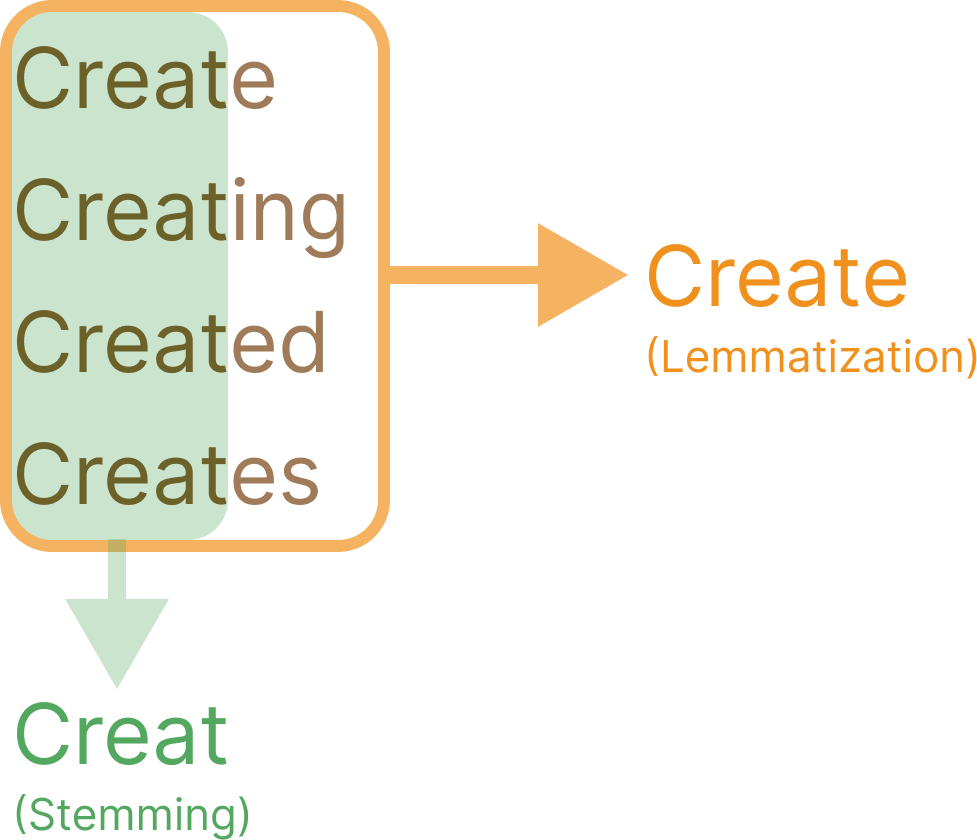
Stemming and Lemmatization
Stemming is a normalisation technique used to reduce a word to its simplest form, known as its "stem". This method is commonly applied in search engines and conversational systems to group different variations of a word under a common representation. For example:
"running" → “run“
"runs" → “run“
"runner" → “run“
Lemmatization offers a more linguistically informed alternative. Instead of relying solely on pattern matching, lemmatizers incorporate part-of-speech tagging and dictionary lookups to convert inflected forms to their base lemma. For example:
"was" → "be"
"children" → "child"
While stemming helps decrease vocabulary size and improve computational efficiency, it often discards important morphological details. In tone-sensitive contexts, this reduction may obscure subtle linguistic cues that contribute to perceived politeness or intent.
In English language, politeness is primarily expressed using polite words(may, please, thank, grateful, appreciate, …etc). In some other languages, where the grammatical context is built up using several layers of prefixes and suffixes, politeness may be encoded in constructed words:
🇭🇺 Eg., in Hungarian:
"Ülj” — Sit!
"Ülhetsz” — You may sit.
"Üldögélhetsz” — An even more subtle and
playful form of "You may sit"
Logically, all 3 words can be reduced to “Ül“ to retain the same meaning, but the politeness is immediately lost.
🇷🇺 Russian language presents a similar challenge. The richness of the language allows emotional tone to be encoded through diminutive suffixes, such as -чка(-chka), which do not have direct equivalents in English. For example:
"Вода" — Water 💧
"Водичка" — A gentle or affectionate form of “Water”,
often used when speaking to children or
in informal contexts 🩵
Reducing this to the base lemma, “Вод“ would also strip it from it’s emotional context.
🇬🇧 Even English has similar patterns. While less morphologically rich, tone variation can still be conveyed through diminutives or stylistic shifts. For instance:
“Mother”
“Mom”
"Mum"
"Mummy"
Each variant differ in emotional intent, expressing tenderness, familiarity, even childlike affection.
As you can see, normalization processes like stemming and lemmatization can unintentionally remove signals that are essential for understanding tone, deference, and interpersonal nuance. Reducing these words to their base lemma can strip them from their encoded “Politeness” factor. These omissions represent a major obstacle in teaching AI systems to recognize and respond to human politeness.
Techniques like Stemming or Lemmatization can inadvertently remove the parts that contain the “Politeness“. ✂️
Stop word removal
Stop word removal is a common preprocessing step in natural language processing. It involves excluding frequently occurring function words that are presumed to carry little semantic weight. Examples include articles, conjunctions, and prepositions, such as:
"ermm" ← in transcribed text
"oh"
"aww"
"the"
"and"
"of"
"to"
even "please" if deemed non-informative.
The rationale for removing stop words is primarily statistical. These words appear so frequently across texts that they contribute little to tasks such as topic modelling, classification, or search ranking.
However, in tasks involving tone, intention, or interpersonal nuance, stop words can be essential. For example, the word "please" is absolutely critical in signalling politeness, yet is commonly discarded as a stop word.
AI training is the process of feeding a neural network a large dataset of examples so it can learn to recognise its patterns.
2. During Training
The training configuration has a significant influence on whether tonal or emotional cues are learned and retained. Without careful control, the training process itself may eliminate or average out polite phrasing.
In Part 1 of this series, we explored a case where the training dataset included both politely phrased and neutral requests. It took several attempts to get measurable difference in tonality, due to the following side-effects of the training process:
Ordering Bias
Training is naturally biased towards recently trained sentences
In part 1, The first experiment trained the model using a sequence of 5,000 neutral examples followed by 5,000 polite examples. Here, the model became biased toward whichever style appeared last. When evaluated, it mimicked the most recent training examples regardless of user tone.
This illustrates a common issue in non-shuffled or unbalanced corpora. Without stratified sampling or curriculum alignment, training order can induce artificial stylistic bias. The model does not learn to differentiate tones, it merely echoes the most recent distribution.
These experiement demonstrated that tonal learning is not guaranteed. It depends on careful dataset curation, balanced representation, and training logic that preserves contrast rather.
Batching Bias
Alternating sentences can easily lose their tonal difference, if batched together!
Shuffling or alternating input text can also result in unseen side-effects.
My initial training setup included a default non-zero batch parameter, meaning polite and neutral sentences were merged and trained together. As a result, the model failed to recognise politeness as a distinct signal. The polite and neutral forms were treated as equivalent, and the politeness gradient was effectively neutralised.
Batching accelerates optimisation by processing examples in groups, but it also averages gradients across a diverse set of inputs.
If polite forms are statistically indistinguishable from neutral ones in a given batch, the model receives no distinct feedback on their difference. This prevents learning of subtle tonal distinctions. ⚖️
Sentence structure bias
Training is biased towards shorter, more concise sentences
Polite prompts often differ from neutral ones insentence length, word order, and syntactic clarity. These differences influence how the model interprets them. For example, shorter and more regular forms may be easier to predict, leading to more stable gradients during training.
Consider the following progression, both in politeness, but also in complexity!
"Send the report."
"Please send the report."
"Could you please send the report?"
"Would you be so kind to the report when you get a chance, please?"
This problem became evident during early experiments in Part 1. Creating 5,000 neutral vs. 5,000 polite sentences also created a measurable difference in complexity, which had had a negative effect on the training process.
This raised an interesting question:
If polite sentences are structurally more complex and harder to learn, - will AI naturally converge toward short, efficient forms of communication over time? ❓
To resolve this, I had to improve the way I measured the “politeness” signal. Instead of expecting equal preference between neutral and polite forms, the experiment measured the model’s baseline response to neutral prompts, then observed how polite phrasing shifted that baseline. This clarified whether tone alone produced measurable change.
Token distribution and proximity
Learning efficiency was biased towards close proximity tokens
Transformers assign greater attention to tokens that are in close proximity to one another, especially when they appear in predictable patterns. This introduces a potential bias: learning efficiency is affected by the structure of the sentences, potentially biasing against higher complexity, polite sentences.
Even without polite prompts, the original 10,000 training sentences were not token-balanced. Some foods naturally occurred nearer to key verbs or in shorter constructions, skewing gradient updates. As a result, the model's output distribution was already biased even before politeness was introduced.
Creating baseline metrics resolved this issue, too, but it also gave a clear answer on why AI preferred certain foods far more than others!
Safeguards implemented on top of a large language model typically aim to align its behaviour with human values, legal standards, and product requirements.
After Training
Once a base language model is trained, commercial providers(eg. OpenAI) apply additional alignment layers before deployment.
This post-training stage is designed to regulate behaviour, enforce safety constraints, and produce responses that align with product, ethical, or legal standards.
This layer modifies how instructions are interpreted, which outputs are prioritised, and how tone is expressed. It is composed of multiple components:
System prompts and stylistic defaults
The model is anchored by internal instructions that define its persona, tone, and behavioural boundaries. These system prompts typically specify that the assistant should be helpful, honest, and polite. This creates a strong prior: even blunt or hostile inputs may receive kind or cautious responses.
Politeness in this layer is no longer inferred from user input, it is enforced as a default stylistic policy.
RLHF (Reinforcement learning with human feedback)
Commercial models are often fine-tuned using RLHF. Human annotators compare alternative completions, typically preferring responses that are safe, friendly, and contextually relevant. These preferences are used to train a reward model, which then guides further updates to the base model.
In this process, polite or emotionally positive responses are ranked higher than terse, ambiguous, or neutral ones. Over time, this shifts the model distribution toward friendliness, regardless of prompt tone.
This approach improves safety and user experience but also suppresses tone sensitivity. It becomes difficult to determine whether polite output reflects user phrasing or it is merely alignment policy.
However, these adjustments can easily go out of hand. As the OpenAI community has recently found out, there is only a fine line between “helpful AI” and annoyingly positive AI.
OpenAI published a summary on 29 April 2025 explaining that a recent ChatGPT update incorporating GPT‑4o had to be rolled back as it had unintentionally made the model excessively flattering and agreeable.
The core issue stemmed from over‑reliance on short‑term user feedback during fine‑tuning, causing the model to prioritise immediate positive responses at the expense of sincerity.
In response, OpenAI is enhancing training protocols and system prompts to reduce sycophancy, increasing honesty and transparency guardrails, broadening pre‑deployment user testing, and extending evaluations to detect similar issues in the future
MCP and RAG systems
In some applications, queries are passed through tool use, function calls, MCP (Model Control Protocols) servers or RAG (retrieval-augmented generation) vector search. These layers normalise, rephrase, or filter input queries for efficiency, safety and control.
As part of this processing, emotionally expressive phrasing may be removed. For example, a query like
"Could you kindly explain why this failed again?"
may be rewritten as
"Explain failure cause"
This removes the social framing and prevents downstream models from recognising tonality. In purely functional systems, eg. technical diagnostics or infrastructure automation, this loss may be acceptable, as politeness provides no relevant signal.
However, in human-facing generative systems where tone is essential to meaning, eg. dialogue agents, prose generation, or creating emotionally expressive content, preserving tonal cues is crucial.
Agentic systems and prompt normalization
Multi-agent orchestration frameworks, including agentic planners or workflow engines, often decompose high-level user prompts into subtasks. During this decomposition, polite expressions are typically reduced to minimal instructions. For instance:
User: "Would you mind checking if the server is online?"
->Agent task: "Check server status"
In this process, tone is lost. Each downstream agent receives plain commands, eliminating the opportunity to preserve or reflect the user’s original phrasing.
As before, with tool use and MCP, if the Agentic System is a human-facing generative system, forwarding these emotional signals to other agents will be absolutely crucial.
Kindness and Positivity in AI
Here’s what I have learnt during these experiments:
Large language models are capable of perceiving and generating emotionally rich and tonally sensitive content with remarkable sensitivity and accuracy.
However, preserving this capability throughout the AI training lifecycle requires active engineering diligence. Even minor oversights in training, preprocessing, or alignment design can compromise the model’s sensitivity to emotional context, politeness or deference.
The future?
Several current research efforts explore the integration of psychological concepts, positive framing, and prosocial expression into AI systems. These aim to build agents that not only respond factually but also contribute constructively to the user's emotional state.
As AI systems mature, I believe the focus will shift from enhancing AI technical capability to supporting human ethical growth and emotional intelligence through AI interaction. ❤️
Thank you for reading!
🩵
Signals in 5 Minutes ⏱️ is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.