Can saying "please" actually change an AI’s answer? Turns out, it can.
In Part 2, we’ll open the hood to see how and why - using tokens and embeddings.
First, what’s a token?
AI doesn’t read text like humans do. It breaks everything down into tokens – think of them as the smallest digestible chunks of language:
Well, that was easy, so tokens are just words converted into numbers, right? Well, not quite! Some natural languages and models can be more complex than others:
Depending on the language and the model, a token might be:
A whole word: hello
A sub-word: hel, lo
Or even punctuation: . or ,!
Consider these Hungarian “sentences“:
🇬🇧 “We should ho home“ 🇭🇺 “Hazamehetnénk“ ← Yes, it’s only 1 word‼️
Or:
🇬🇧 “For your repeated behaviour of being impossible to desecrate“ 🇭🇺 “Megszentségteleníthetetlenségeskedéseitekért“ ← Yup, still just 1 word‼️
(Note to the reader: don’t learn Hungarian! 🙅♂️)
As you can see, tokens split sentences (and sometimes even words as you saw above) into meaningful chunks. (Well, meaningful to AI, not for us!) Think of these as lego blocks that construct words, then sentences, then larger texts.
But - these individual blocks don’t contain any “meaning”, yet. They need to be turned into high dimensional embeddings - that is where the properties like politeness or tone are captured.
Ok, what’s an Embedding?
This is where the magic starts!
Once a sentence is tokenized (ie. turned into a bunch of numbers), each token is turned into a vector, ie. a list of numbers. (So we end up with a “bunch of bunch of” numbers!) That list is called an embedding.
Vector embeddings are: numerical representations of data points, effectively creating "digital fingerprints" for words, sentences, even images, music, video or any other data, allowing machine learning models to understand and compare them.
Ok, that was a mouthful, but basically it’s just this:
Embeddings are a bunch of numbers that tell AI that a dog is a furry hairy bitey barky waggy licky creature. 🐕
Essentially, the embeddings capture meaning in high-dimensional vector space.
What’s a high-dimensional vector?
Remember our book shelf from Part 1?
In that example we arranged the books by how “nice“ they were. In embeddings terms, this would be a single dimension, represented by a single number, ranging from -1 to 1:
On this imaginary bookshelf books that are similarly compassionate would get similar scores, ie. they would be closer to each other on the left.
Of course, a single dimension wouldn’t be enough to organise our books. We want to organise them by many different properties: topics, authors, language, complexity, size of the book, weight of the book, colour of the book …etc.
Words in a 2 dimensional vector might look like this:
“Please“ and “Grateful“ are similar, so they are closer to each other, whereas “Hate“ is much further away.
(Yes, but what do the X and Y axes represent? Great question, hold that thought, we’ll get back to that in a bit, I promise!)
The more dimensions we add, the more fine-grained and accurate the model becomes - as it can capture more and more aspects or meanings of the contained words.
Thinking in multi-dimensional space
For us, humans, it’s fairly easy to think in 1, 2 or 3 dimensions and conceptually visualise spacial relationship between objects in a 3D space.
Beyond those 3 dimensions we are a little bit out of our depth. Maybe we can add one more and call it “time”, but if someone said:
“Can you imagine a zebra galloping in a 9 dimensional space?” 🦓 - we would need to replace our daily protein shake with ayahuasca to grasp that.
AI - on the other hand - can work with more than 3D or 4D or 9D - it can work with hundreds of dimensions!
Google’s well-known word2vec model represents all dictionary words in a 300 dimensional space, while:
Internally, ChatGPT “thinks“ in a 12,288(‼️) dimensional space, ie. every token gets converted to a 12,288 dimensional vector! 🌌
Let that sink in. 🚰
4 dimensional cube
While our brains melt trying to visualise a 4 dimensional cube, ChatGPT happily “thinks” in a 12,288 dimensional space, real time, serving millions of users simultaneously. Next time you call AI stupid for not knowing how many R-s are in strawberry, think of this! 🍓🤭
Small clarification, before we continue:
The OpenAI Embeddings API, such as text-embedding-ada-002 returns vectors that are exactly 1536 dimensions. This API is available for engineers to convert words, or even word sequences to a fixed embedding.
However, this differs from the internal vector spaces used within ChatGPT itself, which is a larger language model like GPT-4 or GPT-4o. These internal models have much larger embedding and hidden state dimensions (e.g. 12,288), which are not exposed directly via the Embeddings API.
So, when we do experiments, we are looking at the 1536 dimensional vector space, but when we use ChatGPT for inference, internally it uses the much higher dimensional vector space.
Luckily for us, puny humans, we don’t need to think in 13 thousand Dimensions. To understand what AI does, we can think of each token as a configuration of sliders, ranging from -1 to 1. Two words are similar if their slider configurations are similar:
Eg. “Thankful“ and “Grateful“
So, what are these distinct dimensions?
This is one of the amazing things about AI: We don’t know.
Each number in an embedding vector is learned through training. The model doesn’t start with any built-in understanding of any categories like “politeness“, it learns these properties by:
Reading tons of text (books, websites, code, recipes...)
Trying to predict something (e.g. what word comes next, or which words go together)
Adjusting the numbers in the embeddings to improve those predictions
This process is the called training, and it's done using gradient descent, a way to nudge the numbers slightly in the right direction, over and over again, until the model gets really good.
Each dimension in the vector might encode something like:
Positive vs negative emotion
Concrete vs abstract
Polite vs rude
And so on...
But we don’t assign labels to those dimensions, the model discovers them, in combinations that make sense mathematically.
For us, it’s a black box. It’s how the AI makes sense of the world.
Note: If you are interested in how embeddings are created, you can read about the 3 most popular methods here: Word2Vec, GloVe, andBERT.
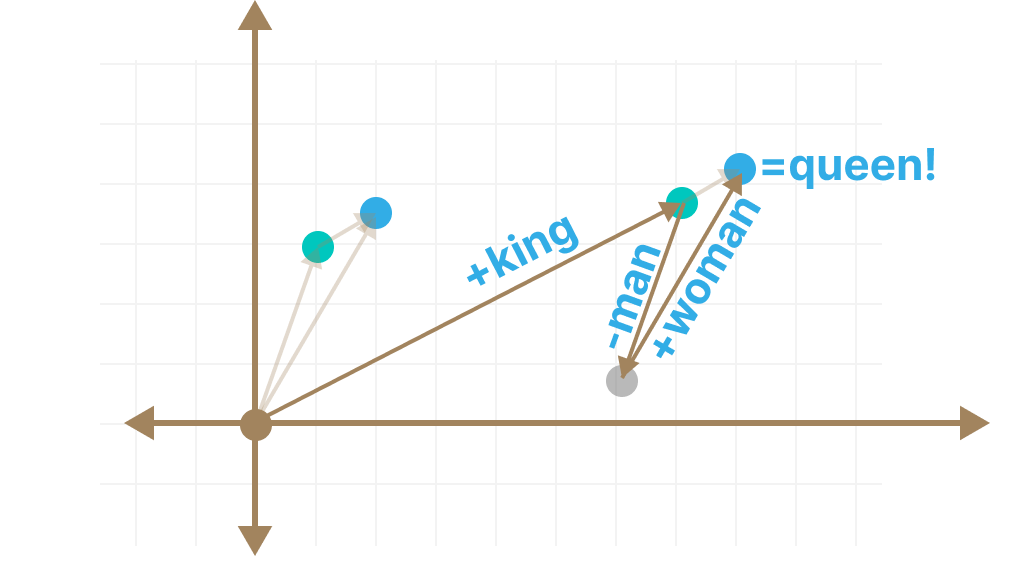
Kings and Queens
One of the most incredible aspect of embeddings is that you can perform vector operations on them, like the famous equation:
King - Man + Woman = Queen
We don’t really know which of the 1536 dimensions in the vector represent being male or female, but we know that the same difference exists in word pairs like
man-woman
king-queen
waiter-waitress
…etc.
Since the relationship between these word-pairs are similar, we can also assume that they are laid out similarly in the vector space:
woman - man = queen - king
This gives us the ability to perform vector operations like this:
AI doesn’t associate by exact words. It associates by vector embeddings. 👯
That means it understands language based on closeness in a high-dimensional space, and not by matching keywords.
Just like queen, monarch, and princess cluster together due to shared semantic meaning, words like “please”, “thank”, and “grateful” are also embedded in close proximity of each other.
Think of this as a "gratitude cluster." When you include polite language in a prompt, you're subtly shifting the input vector toward that cluster.
So by operating in a context of “gratitude,” your prompt can subtly shift the request into a region of the vector space where there was more politeness and gratitude in the original text AI learned from.
Contextual Embeddings
Notice that we only have “thank“ in the diagram above, instead of “thank you“.
This is where Contextual embeddings come in. They capture the meaning of a word by considering its surrounding words. For example:
"bank" in river bank is not the same as "bank" in investment bank
"you" in Thank you! has a different tone than in “Are you sure?”
Ok, how does this work with full sentences and larger text?
Sentence Embeddings
As you can see in this slightly NSFW video from Burning Man, sentences and longer texts are more than just the sum of their words.
The word order matters, the context matters. Even two identical sentences can have completely different meanings based on their surrounding context!
For example, “I can fish“ can have two different meanings:
“I can fish”
This is what Sentence Embeddings solve. Sentence Embeddings are derived from contextual embeddings, they capture the semantic meaning of the entire sentence or larger texts, creating a clear context and allowing for tasks like semantic search and clustering.
Each sentence is represented as a point in the same high-dimensional space. Just like words, sentence embeddings can be compared and clustered based on proximity. 🌌
Let’s pause here for a second, as this is incredible.
Imagine a vast, high-dimensional space where every sentence ever written - or yet to be written - has a precise point (or star) that represents its meaning:
“I like lettuce” and “I like celery” are similar, so they are closer to each other, while “He drives a yellow tractor“ sits somewhere else in the embeddings Universe. 🚜
Every time you say something, it gets mapped to an exact position in that space, with a measurable distance to every other sentence ever spoken by anyone who has ever lived.
And here’s the mind-blowing part:
That distance is quantifiable. You could compare the embedding of your sentences to the sentences said by the Dalai Lama or written by Shakespeare - and get a similarity score between 0 and 1.
How would your sentences score?
Ok, let’s continue.
Cosine Similarity
Sentences with similar tone, intent, or meaning will naturally group together, even if their wording is different. On the other hand, sentences with slightly different politeness or tone, will also have a slightly different point in the vector space.
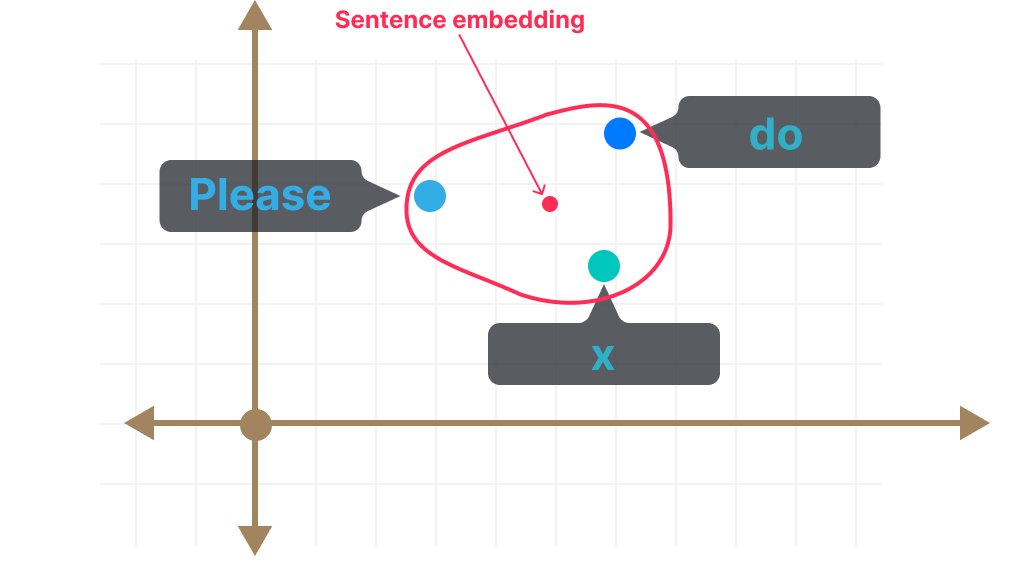
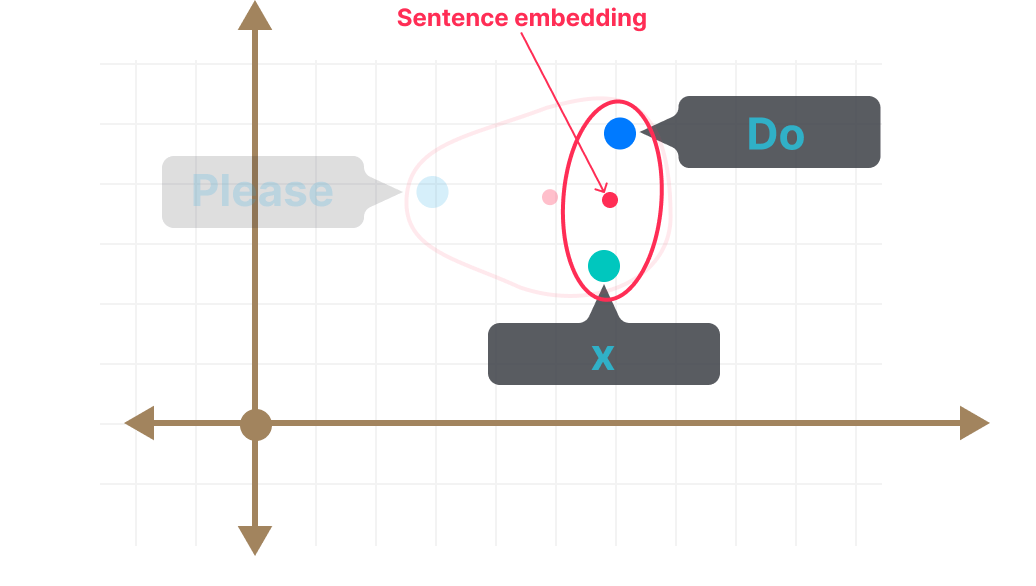
Consider the sentences:
“Please do x”
Versus:
“Do x”
Do x
This is the slight shift we saw in Part 1 - where politely worded sentences got slightly different sentence embeddings - and ranked higher when retrieved via polite prompts.
Ok, let’s test some politeness embeddings!
The OpenAI API provides a convenient way of retrieving word embeddings in a few lines of code:
As a quick test let’s retrieve the embeddings of the following 10 words to visualise them in a 2D space:
embeddings of positive and negative words mapped to a 2D space
This beautifully shows that the model understands emotional context and clusters similar emotions. This is a great start, so let’s add more words:
Embedding of compassionate and hateful words naturally form clusters!
Now this is interesting!
The clustering is even more pronounced, showing the power of embeddings, how words can naturally cluster from compassionate to harmful! This is our imaginary bookshelf in action! ❤️
But - we have also got some unexpected outliers! Notice the position of kill and war in the diagram.
Why are “Kill” and “War“ so close to “Love“ and “Peace”?
Maybe these concepts often co-occur in emotionally charged writing? I would love to hear your ideas in the comments!
So much more to cover, but substack is showing the “Post too long“ message, so it’s a good time to wrap up.
Here's what we have discovered in Part 2!
AI doesn’t just read words, it positions them in multi-dimensional space.
Even tiny additions like "please" can shift embeddings into a different region.
LLM-s already understand emotional context and cluster similar emotions.
This is how politeness affects data retrieval - not because the AI is moral or emotional, but because "please" literally shifts the geometry of the input prompt. 🍓
I hope you enjoyed this article. If you haven’t already, please subscribe and you’ll get notified when the next part is out!
Signals in 5 Minutes ⏱️ is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber. 🙏
Bonus content!
I also wanted to give an example of clustering full sentences. Here are 10 spiritual quotes and 10 violent ones. I want to see how OpenAI creates embeddings for them, without any context or instructions.
If we are lucky, these sentences will naturally be clustered by their similarity - in this case by their level of compassion and kindness.
This was genuinely impressive. The diagram shows that in high-dimensional embedding space, sentences expressing kindness and compassion tend to cluster together.
This isn't because the model “understands” morality in a human sense - it’s the result of statistical learning. During training, the AI was exposed to millions of examples where kind and harmful language appeared in very different contexts. Over time, it adjusted the embedding vectors to reflect those patterns.
Seemingly, sentences that express empathy, care, or gratitude are now positioned near each other in vector space - not by design, but as a natural consequence of the training process. (And the hard work and ongoing manual tweaking of the model by OpenAI team! ❤️)
In other words, kindness became a measurable and visually recognisable feature. ✨
In high-dimensional vector space, there is a region where all kind and compassionate thoughts live.