Imagine an exam so comprehensive and complex that no single person could prepare for it in a lifetime.
This is Humanity’s Last Exam, a benchmark designed to test the limits of knowledge, reasoning, and general intelligence of AI.


Humanity’s Last Exam
Humanity’s Last Exam (HLE) is a new benchmark designed to evaluate the capabilities of advanced AI systems against a broad cross-section of human academic knowledge.
HLE was created by the Center for AI Safety in collaboration with Scale AI , finalised in April 2025. It was introduced in direct response to the saturation of existing benchmarks such as MMLU, which large language models (LLMs) are now solving with over 90 percent accuracy. This diminishing headroom limits the ability to meaningfully differentiate new models.
HLE aims to restore meaningful discrimination at the upper boundary of model capabilities. It does so through a large-scale, multi-modal benchmark comprising 2,500 closed-ended questions across numerous academic disciplines. Each question has a known solution, is unambiguous, and cannot be answered reliably through retrieval methods.

Composition of the benchmark
Humanity’s Last Exam has:
2,500 validated questions with automated grading
Multi-modal components, including image-based reasoning tasks
Closed-ended formats, primarily multiple-choice and short-answer
All content is in English and assumes fluency in specialist terminology
Contributions from approximately 1,000 subject-matter experts across more than 50 countries

What are the topics?
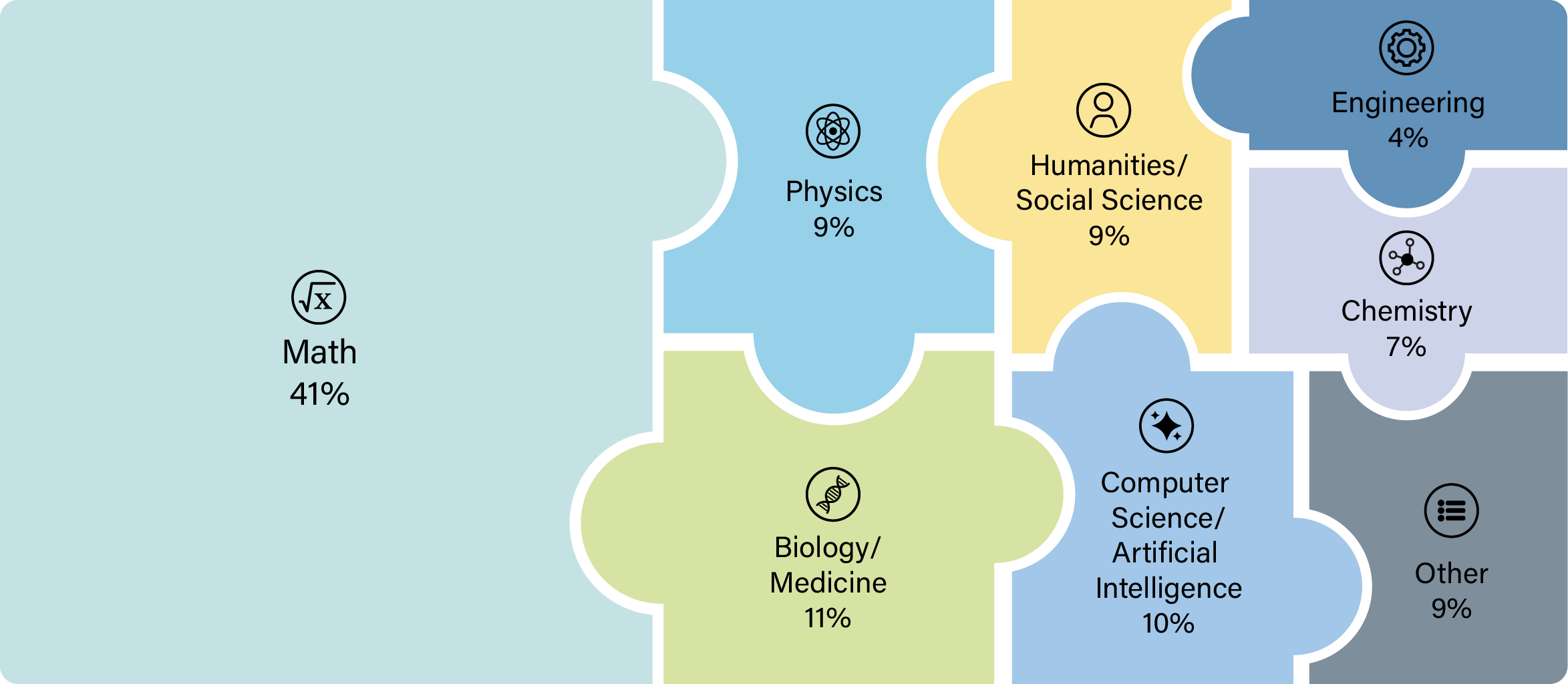
HLE covers questions across all major disciplines including mathematics, physics, biology, medicine, humanities, social science, chemistry, computer science, history, economics, and philosophy and more.
In a nutshell:
Every field of science, from astrophysics to zoology
Every major professional exam topic, from law to medicine to economics
Every creative domain, from composing poetry to analysing Renaissance art
Coding, maths, ethics, education, design, policy, translation
It essentially covers the collective syllabus of human civilisation.
🌍
Each question has been explicitly constructed to require reasoning. They are not searchable, the answers can’t be “looked up”.
Questions that could be trivially answered through pre-trained content or retrieval heuristics were discarded during validation.

Can a Human pass this exam?
The Humanity's Last Exam benchmark spans over thirty academic and professional disciplines, each represented by multiple difficult, closed-ended questions.
To understand the scale of this challenge from a human perspective, here’s an estimate on how much time it would take to reach confident, exam-level mastery.
Let’s assume each subject requires at least two years of intensive study to reach postgraduate competence.
2 years x 30 primary domains within HLE = 60 years of full-time study.
This is with no breaks, no cognitive fatique.
In practical terms, no individual human could complete
the Humanity's Last Exam syllabus within a lifetime.
🌳
HLE reflects the accumulated expertise of thousands of domain experts. It is not designed for and not a realistic syllabus for any human being.

Motivation for the benchmark
The HLE benchmark addresses several emerging problems in model evaluation:
Benchmark saturation: Current models approach human-level scores on most academic tasks, reducing differentiation
Misleading generalisation: Performance on older benchmarks often reflects memorisation rather than true reasoning or synthesis
Policy ambiguity: Without a clear measure of high-end capability, risk assessment and governance remain speculative
HLE provides a clear reference point to inform safety research, capability forecasting, and regulatory decision-making. Its construction was inspired by the need for a more discriminating, stable, and forward-compatible benchmark.

Who are the current “winners”?
The following models achieved the highest scores in the April 2025 public benchmark release:

Google’s Gemini 1.5 Pro: 21.6 percent accuracy (public set)
OpenAI’s o3-high: 20.3 percent
Anthropic’s Claude Opus: 10.7 percent
Meta’s LLaMA 3 Maverick: 5.7 percent

These results reflect performance on the full, 2,500-question public test set. A private test set has been retained to ensure that improvements are not the result of overfitting or benchmark leakage.
Models are also evaluated for calibration, which refers to the correspondence between predicted confidence and actual correctness.
Currently, across the board, all models exhibit poor calibration on HLE, suggesting limited meta-cognitive accuracy under uncertainty.

Epistemic value
HLE contributes measurable clarity in the following areas:
AI capability bounds: Establishes a conservative ceiling for closed-ended academic reasoning
Scientific transparency: Provides a replicable, auditable methodology for capability testing
Longitudinal tracking: Offers a stable comparison point across model generations
Policy anchoring: Supports informed governance with concrete indicators of model reliability and limitation
Unlike open-ended tasks (e.g. essay writing or dialogue), HLE permits objective evaluation without human raters, enabling consistency and comparability over time.

Limitations of scope
It is important to note what HLE does not measure:
Emotional intelligence, creativity, or ethical judgment
Generalisation beyond academic knowledge
Agentic decision-making or real-world planning
Multilingual comprehension (HLE is English-only)
HLE is best understood as a narrow but deep test of academic knowledge and structured reasoning, not a comprehensive measure of general intelligence.

That’s all for now!
Humanity’s Last Exam represents a rigorous, stable, and globally coordinated effort to assess advanced AI performance at the boundary of human academic achievement.
Its low scores across leading models suggest that current LLMs remain significantly below expert human performance in structured, multi-domain reasoning tasks.
It is unlikely that another benchmark of this scope and format will be needed in the near future.
Hence the cool name. ✨
Resources
Bonus Content!
Here are a few more questions from the exam. It’s so fascinating to flick through them and see how much Humanity has achieved in our short time on planet. 🌍